This is a typed up copy of my lecture notes from the seminar at Linköping, 2010-08-25. This is not a perfect copy of what was said at the seminar, rather a starting point from which the talk grew.
In my workgroup at Stanford, we focus on topological data analysis — trying to use topological tools to understand, classify and predict data.
Topology gets appropriate for qualitative rather than quantitative properties; since it deals with closeness and not distance; also makes such approaches appropriate where distances exist, but are ill-motivated.
These approaches have already been used successfully, for analyzing
- physiological properties in Diabetes patients
- neural firing patterns in the visual cortex of Macaques
- dense regions in [tex]\mathbb{R}^9[/tex] of 3x3 pixel patches from natural (b/w) images
- screening for CO2 adsorbative materials
In a project joint with Gunnar Carlsson (Stanford), Anders Sandberg (Oxford) (and more collaborators), we act on the belief that political data can be amenable to topological analyses.
1st: What do we mean by political data?
We currently look at 3 types of data:
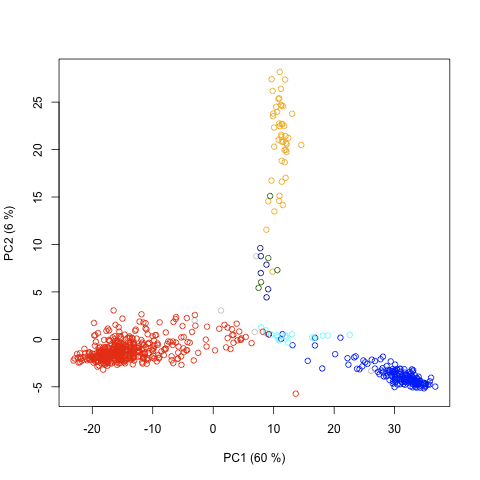
- Vote matrices from parliament:
each column is a member of parliament each row is a rollcall we codify votes numerically: +1/-1 for Yea/Nay
And then we can do data analysis either on the set of members of parliament in the space of rollcalls, or on the set of rollcalls in the space of members of parliament.
Co-sponsorship graphs
Nodes are members of parliament.
A directed edge goes from each co-sponsor to the main sponsor of a particular bill, for all bills.
For Swedish politics, parties end up being strongly connected internally, with coalition mediators appearing in the data.
Shared N-gram graphs
Some turns of phrase, some talking points, get introduced and then re-used by other members of parliament.
We believe that an analysis of N-grams of parliamentary speeches may well give a data analyst tools to capture memetic drift and spread within partliament.
The project is still at an early stage, and the great challenge for us right now is to find value to add — in political science, the grand entrance of classical data analysis was a few decades ago, and much of what can be said about politics with classical data analysis tools has already been said.
2nd: What has already been done?
Political science discovered data analysis in the 90s, and a flurry of political science data analysis papers followed.



3rd: How do we bring in topology?
There are several techniques developed at Stanford for topological data analysis. While my own research has been centered around persistent homology, the one I want to present here is different.
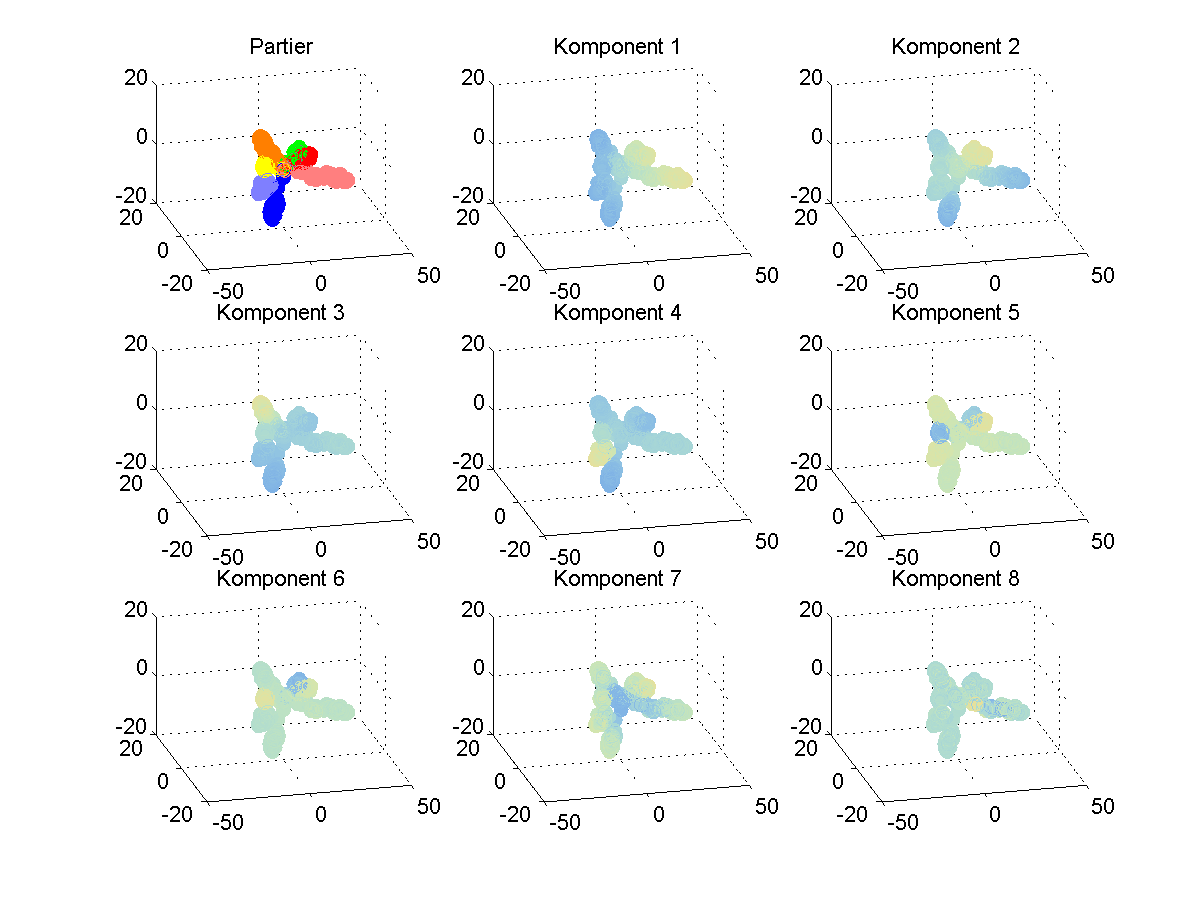
Mapper was developed by Gurjeet Singh, Facundo Memoli and Gunnar Carlsson. It builds on combining nerves with parameter spaces.
Now, if X is a topological space with a coordinate function [tex]X\xlongrightarrow{f}Z[/tex] and Z is (paracompact and) covered by some family of [tex]U_i[/tex], then the collection of preimages covers X.
So, by subdividing each preimage of a set in the covering of Z into its connected components, we get a covering of X subdividing the cover induced from Z.
Thus, if f is sufficiently wellbehaved and the covering is fine enough, the nerve of these subdivided preimages is homotopy equivalent to X, and we have found a triangulation (up to homotopy) of X.

We hope to be able to use these techniques to better understand the way parliaments are structured internally.